友链及友链朋友圈折腾史
友链
友链数据
说到友链,算是入坑 Hexo 博客以后第一个魔改的内容。
当时的魔改的友链还只是在原主题的基础上修改源代码,导致每次升级主题都要进行大量适配工作。
于是第一版的友链(不修改源代码)魔改出现了,其原理是通过 JavaScript 异步请求 giteeAPI,来在前端显示友链信息。gitee 端使用 issue 存储友链,使用户更方便的交换友链。
此处省略大量前端适配及优化方案。
方便的同时也产生了大量问题,其中我最不能容忍的情况如下:
- 交换友链后站点关闭即博主不在维护
- 交换友链后换主题或博客系统导致曾经友链记录全部消失并且不补
因此在 2022 年年初,基于 kkapi 我想要交换友链的小伙伴通过 API 提交交换,并且与用户 GitHub 或者 Gitee 绑定。前端通过自行填写表单的方式提交。
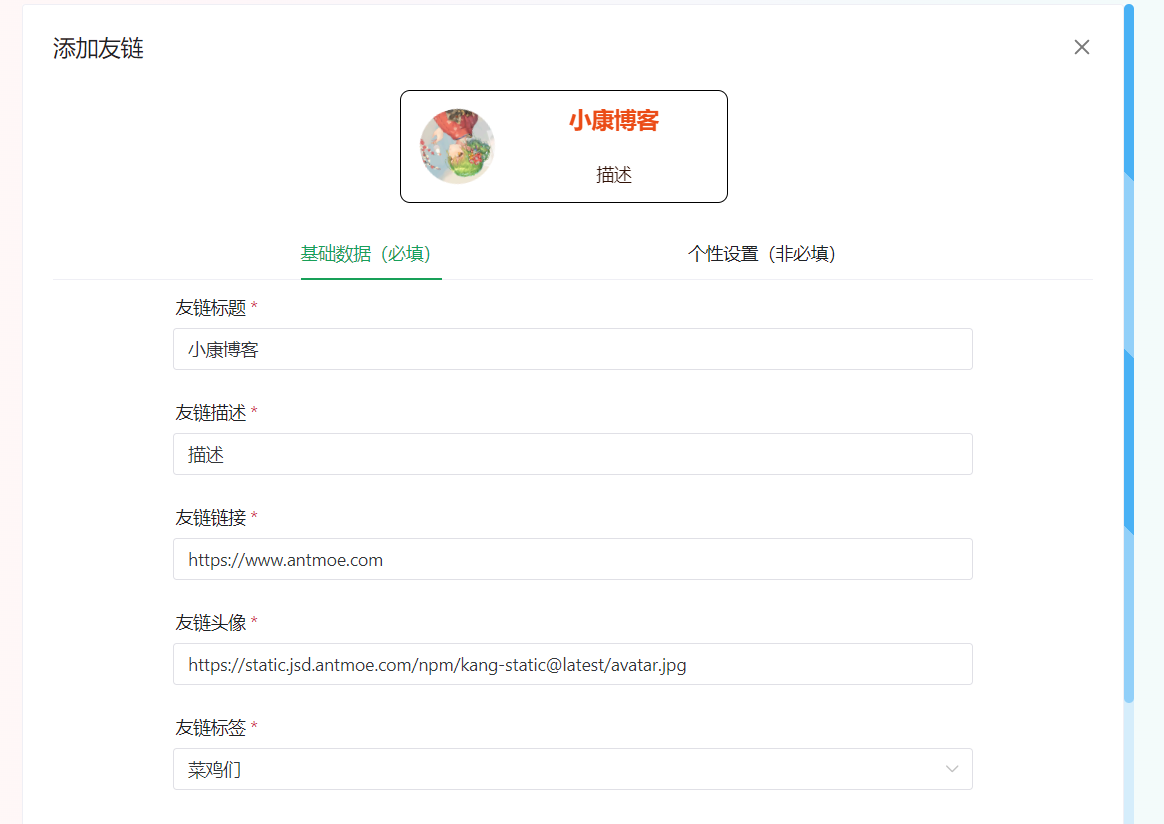
但是此方案的实现过于复杂,且由于出现账号的概念,所以无形中为用户的“账号记录库”增加负担,且在代码维护与安全方面存在很多问题需要完善,因此此项方案作废。
在同一时间,受到乐特大佬的启发,将友链文件放在 GitHub 中,前端通过请求此文件来获取友链信息。
于是我现在的友链诞生了,其大概流程如下:
用户 PR 友链信息->vercel 触发构建->基于 yaml 生成 JSON->部署静态文件(产物)
这样即可以解决交换友链过于简单,导致出现上述两种情况的可能,也能更简单的管理友链。
通过 PR 交换友链,在一定程度上可以过滤掉只是建站玩玩并随便交换友链的小伙伴。也能省掉自己开发维护一套后台管理的步骤。
采用此方案的好处
不依赖于主题
理论上来说,无论现在用的是什么主题都可以这样使用,前提是需要编写对应脚本根据友链 json 生成对应主题友链的样式
数据公开和记录
所有人都可以看到历史修改记录
便于扩展
因为友链数据统一了,因此基于友链的一些项目便可以很方便的生成对应数据
其他
友链前端
最新版的友链前端仅支持上述数据源,并且我个人认为友链这种东西不应该太过于花里胡哨,因此将曾经花里胡哨的部分均会砍掉,只保留最基本的友链。
但是友链的样式还会继续更新。
友链朋友圈
这部分目前只咕了对接爬虫的部分和 API 查询部分,至于前端部分仍未开始。
部署友链爬虫
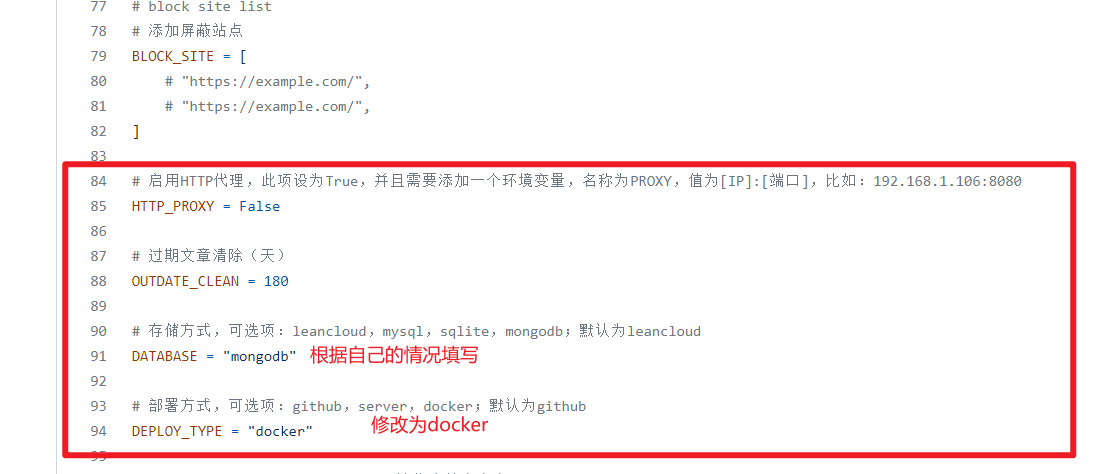
部署友链爬虫我个人比较喜欢的方式是通过docker-compose部署,因为这样我不需要记繁杂的命令,只需要一条命令即可启动。
镜像仓库通过阿里云打包,并且存放在阿里云中,这样拉取速度在我的服务器上能够杠杠的。
部署姿势参考:基于 Docker 安装之安装友链朋友圈爬虫
setting.py配置参考:setting.py
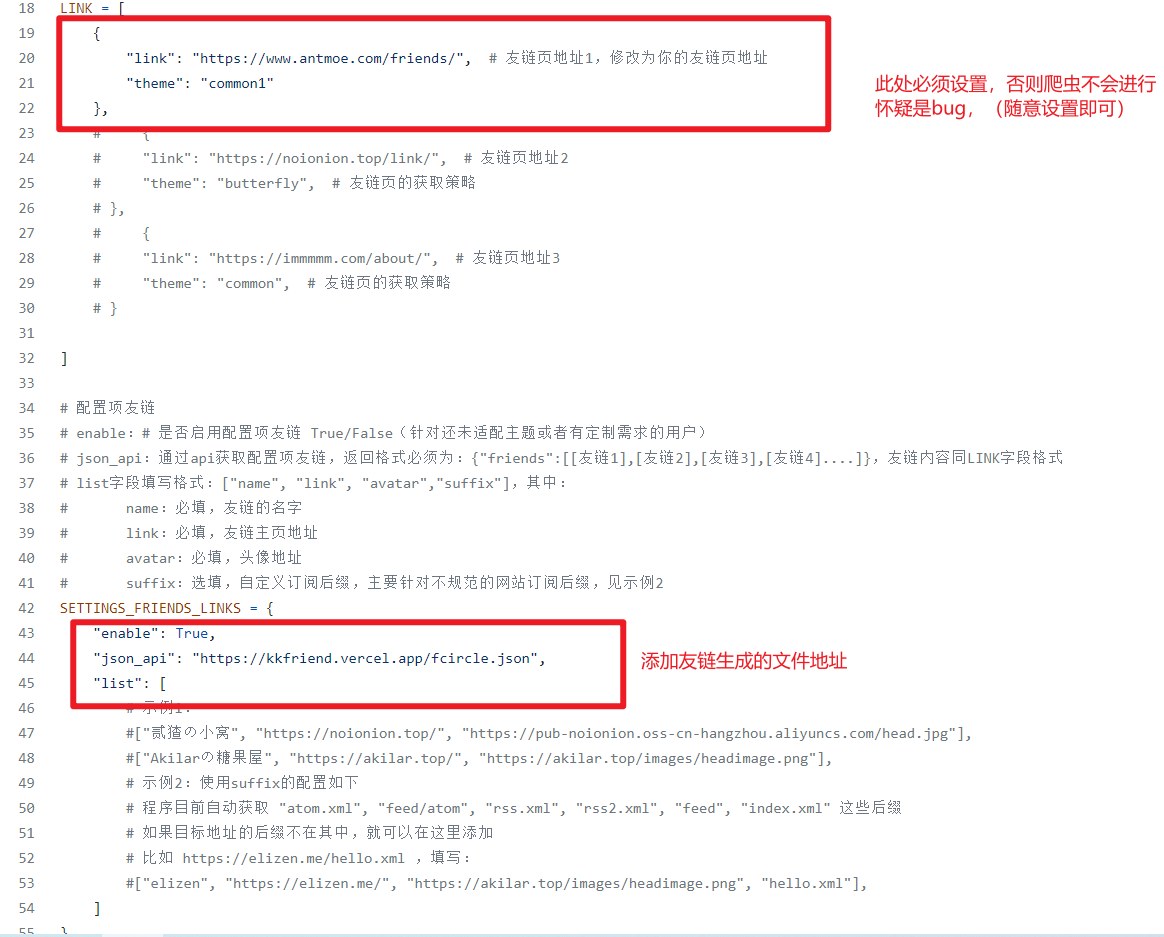
友链爬虫数据源
对于友链爬虫对于我来说只是一个链接 rss 爬虫,为什么这么说呢,因为对于这个程序,我只想让他爬我希望让他爬的链接。例如:你的友链有一个好友整天发的文章是一些推广类文章,那么如何在不删除友链的情况下,不修改源代码的情况下去掉这个链接呢?当然了还存在一种情况,小伙伴交换的友链是
blog.antmoe.com,但是他的 rss 订阅地址是blog.antmoe.com/rss,此时如何告诉爬虫不去爬blog.antmoe.com而是爬blog.antmoe.com/rss呢?
hexo-circle-of-friends新增mongoDB存储和jsonapi方式爬取友链对我来说是大大的友好,起初对于 jsonapi 的提供方式我选择了在 kkapi 生成订阅链接,然后交给爬虫,这种方法起初是没有问题的(虽然现在也没有什么问题)这样可以灵活控制需要爬哪些链接而不受友链影响。
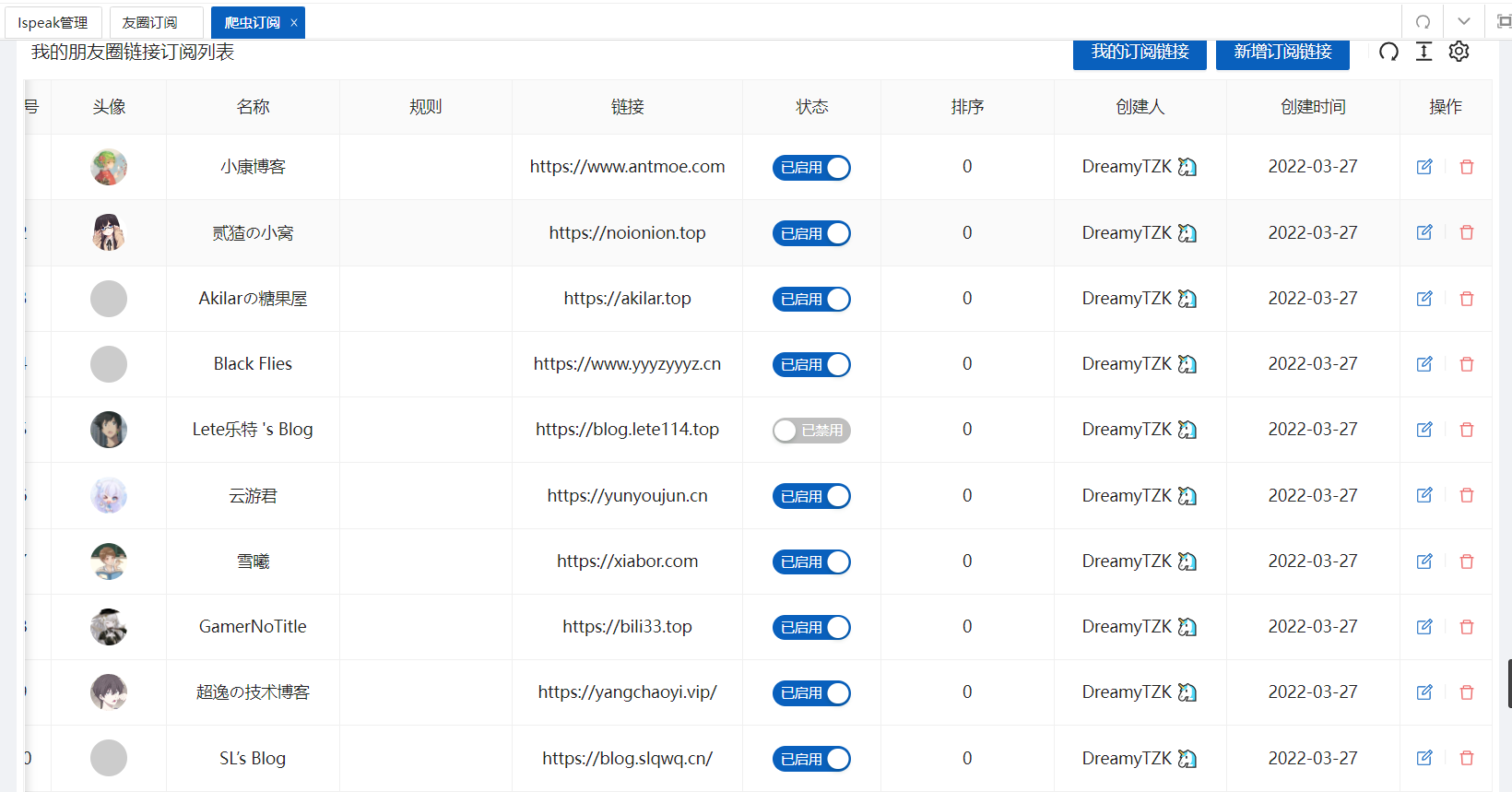
在大多数情况下友链数据与爬虫数据是需要同步的,因此如果只是单独放在后端就需要添加同步友链的接口去同步友链,为了使友链数据与爬虫爬取的数据达到统一,我最终选择扩展上述友链数据,在生成友链数据的同时生成一份用于爬虫的数据。例如:https://kkfriend.vercel.app/fcircle.json
其原理大概如下:
生成友链->提取并过滤所有友链->符合条件则写入文件
为了满足上述中的需要,添加了一下字段来控制是否将友链加入到爬虫队列以及爬虫爬取的地址
1 | # 是否禁用友链爬虫(true表示不加入友链爬虫队列,false表示加入爬虫队列) |
api 部分
重写 api 并不代表否认官方 api,而是因为我不会 python,并且数据格式我并不喜欢,因此选择了重新构建 api。
重构 API 的必要条件
- 基于kkapi
- 数据存储在 mongodb,并且与 kkapi 使用的是同一数据库
目前接口实现
| 名称 | 路径 | 描述 |
|---|---|---|
| 获取全部文章 | /fcircle/all | 用于获取全部文章 |
| 模糊查询 | /fcircle/find | 用于提供部分信息来实现模糊匹配 |
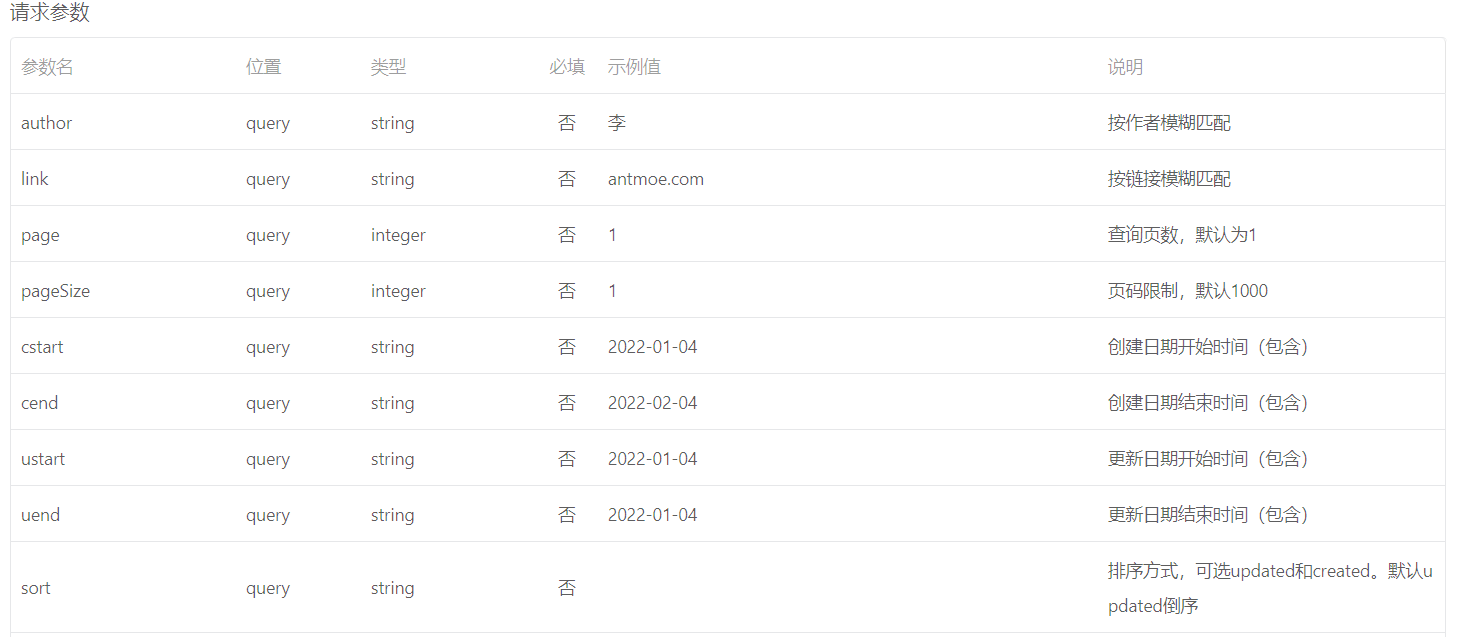
模糊查询接口支持的参数
前端部分
咕咕咕
 wechat
wechat- alipay

